KI-Crawler? Zugriff verweigert!
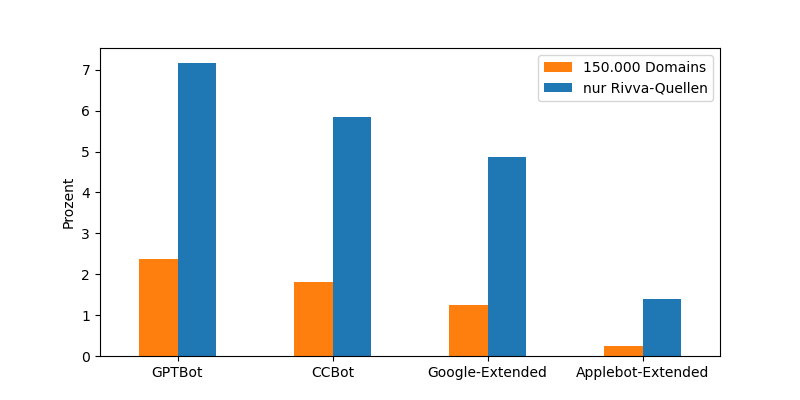
Webstatistik: Wie viele Webdomains verwehren den neuen Webcrawlern jeglichen Besuch ihrer Seiten?
– Heute kucken wir uns mal 150.000 robots.txt-Dateien an: Mich interessierte im Detail, wer die "KI-Crawler" von GPT, Common Crawl, Google und Apple eigentlich überhaupt noch auf seine Website lässt.
Dass mittlerweile fast alle Nachrichtenseiten die GenAI-Bots aussperren, hatte ich ja schon vorletztes Mal über Common Crawl gepostet. Dass offenbar aber generell eine starke Gegenwehr auf dem Weg ist, die eigenen Webinhalte vor der Verwertung durch generative KIs zu schützen, verdient eine zweite, tiefere Betrachtung.
Zum Vorhaben:
- 150.000 Domains nach Zufall selektiert; davon 80% deutsch, 20% englisch; ohne Einfluss, wie lang die Site schon existiert, wie oft verlinkt oder welcher Art von Angebot
- 3,4% davon verbannen gleich mal alle Bots; diese Seiten wollen also auch in keiner Suchmaschine auftauchen und bleiben im Weiteren ohne Betracht – es soll hier nur um explizite Auslistung der KIs gehen
- aktuelle robots.txt abgerufen im letzten Monat
- 150.000 Stichproben können nicht repräsentativ sein, nur eine Momentaufnahme, kein Trend
Das Ergebnis (mit Startpunkten der User-Agent-Kennungen in Klammern):
- GPTBot: 2,4% (August 2023)
- CCBot: 1,8% (März 2008)
- Google-Extended: 1,2% (September 2023)
- Applebot-Extended: 0,2% (Juni 2024)
Anschließend habe ich die Liste nochmal auf Rivva-Quellen eingeschränkt (~10.000 Domains):
- GPTBot: 7,2%
- CCBot: 5,8%
- Google-Extended: 4,9%
- Applebot-Extended: 1,4%
7,2 Prozent ist eine Menge! Color me intrigued…