– Im zweiten Teil der Serie beschreibe ich die Informationsextraktion simpler Fakten. Dabei unerlässlich ist die möglichst geschickte Umformung in eine Standardform, damit einmal gewonnene Informationen vergleichbar, sortierbar und damit durchsuchbar werden.
Im ersten Teil bin ich bereits auf den Aufbau der Zitatesammlung eingegangen, die als Musterexemplar für alle weiteren Datentypen dann auch allen technischen Unterbau für die Verarbeitung natürlichsprachlicher Texte motivierte.
Projektmonat 2 fügt viele weitere Datentypen hinzu für Faktendaten aller Art, die sich in digitalen Texten verbergen können.
Faktenextraktion
Text referenziert in vielen Fällen wertvolle Kerninformationen. Etwa:
Datums- und Zeitbeschreibungen in unterschiedlichsten Darstellungsformen,
Geldbeträge nebst Währung,
Prozentangaben,
Mengenangaben nebst Maßeinheit,
diverse Zahlwörter.
Zudem treten diese Angaben in verschiedenster Gestalt auf:
absolut ("65 Minuten lang") oder
relativ ("gestern Abend", "50 Kilometer weiter", "vor zwei Jahren", "ein Jahr nach Einführung"),
exakt ("fünf Jahre") oder
ungenau ("einige Eigentümer"),
Grundzahlen ("zwei Listen"),
Ordnungszahlen ("bei jedem dritten Mietspiegel"),
Bruchzahlen ("ein Viertel", "drei von vier Kommunen", "nach einem halben Jahrhundert"),
Intervalle ("vorige Woche", "nach dem 1.10.2014", "maximal 5 Jahre", "Rente mit 63"),
usw. usf.
Wie das menschliche Auge können wir Parsing-Algorithmen dazu trainieren, derartige Textstrukturen zu identifizieren:
Weiß der Mensch diese Informationen noch augenblicklich in einen Kontext zu stellen, kann das Elektronenhirn hingegen oftmals nicht von selbst beurteilen, ob seine Ergebnisse plausibel sind. Wahrscheinlichkeiten geben daher den Grad an Gewissheit an.
Normalisierung temporaler Ausdrücke
Tauchen im Text zeitliche Angaben wie "gestern Abend" oder "vorige Woche" auf, müssen wir sie relativ zu einem Referenzdatum auffassen: in aller Regel dem Veröffentlichungsdatum des Artikels, manchmal wiederum in Bezug zu einem bekannten Ereignis ("ein Jahr nach Einführung") oder eines vorher genannten Objekts ("50 Kilometer weiter").
Letztlich wollen wir, wenn ein bestimmtes Ereignis zu einem nur umschriebenen Zeitpunkt stattfand, dieses Ereignis in kanonischer Form und mit möglichst spezifischen Zeitkoordinaten in unserer Faktendatenbank ablegen. Nach "gestern Abend" können wir nicht universell suchen, nach Ereignissen in einem bestimmten Zeitraum hingegen schon.
Einfache Suchabfragen
Das Extrahieren von Fakten lässt sich natürlich auch als Aufgabe zum Auffüllen von Wissens-Slots auffassen. Wollten wir beispielsweise für eine Wissensbasis den Slot ("Mietpreis", "2014", "Kreuzberg", ?) füllen, können wir unseren Textkorpus nach Textstellen absuchen, die eben diesen Kontext ("2014", "Kreuzberg") erfüllen. (In Monat 5 kommt dafür noch Relation Extraction ins Spiel.)
Mittelfristig sollen mächtigere Suchoperatoren wie "near: Context" und "between: Num1 and: Num2" es ermöglichen, relevante Treffer über sogenannte Fuzzy Queries auch in schwammiger Umgebung zu finden, wo starre Suchkriterien nur ins Nichts führen würden.
– In dieser Artikelreihe möchte ich aus meinem Google-DNI-Projekt berichten und schon ein paar vorläufige Resultate vorstellen. Im ersten Teil beschreibe ich den Aufbau der Zitatesammlung und führe erste linguistische Konzepte ein.
Die begründende Idee ist, journalistische Inhalte als strukturierte Daten und strukturierte Daten als journalistische Inhalte zu betrachten.
Dazu zerlege ich den Text zunächst in seine Grundbestandteile und setze sie anschließend zu einem Wissensbaum zusammen. Liegen Inhalte in so atomisierter Form vor, lassen sie sich wie Lego-Bausteine verwenden und flexibel neu kombinieren.
Dies wiederum ermöglicht einen hohen Grad persönlicher Medien, wo eine Geschichte für jede LeserIn individuell ausgespielt werden kann, abhängig von ihrem Gerät, ihrem Zeitbudget und ihren Informationsbedürfnissen. Die Entbündelung der Nachricht könnte somit effektiv eine Antwort auf die Entbündelung von Nachrichten sein.
Mein erster Datentyp sollten Zitate direkter Rede sein.
Zum einen wollte ich darüber meine technische Pipeline so weit wie möglich unter Dach und Fach bekommen, und Zitate sind - selbst bei kompliziertem Satzbau - noch einfach genug und berühren dennoch fast alle Verarbeitungsschritte.
Zum anderen liefert die Zitatesammlung interessante Erkenntnisse, kann man mit ihrer Hilfe doch beispielsweise die politischen Positionen der Parteien in Aspekten vergleichen oder ihren Sinneswandel zeitlich rückverfolgen. Beispiel "Mietpreisbremse":
Später in Monat 3 wird noch die Person dazu erkannt und in Monat 5 auch die Beziehung zur Rede, ob jemand also etwas "sagt", "behauptet", "vermutet", "warnt", "kritisiert", ...
Finale Datenstruktur des Wortlauts ist schließlich ein 3-Tupel (oder semantisches Tripel aus Subjekt, Prädikat, Objekt):
("Steffen Sebastian", "sagt",
"De facto läuft die Mietpreisbremse ohne Mietspiegel ins Leere")
Sätze & Sprache
Nur kurz am Rande, da weniger interessant, aber Voraussetzung und oftmals hilfreich: Den Text vorher in Sätze segmentieren und für jeden Satz die primäre Sprache ermitteln.
Leider gibt es manchmal gegenseitige Abhängigkeiten zwischen diesen beiden Aufgaben. Besonders bei Texten aus sozialen Medien kann die Mehrarbeit leicht überhandnehmen.
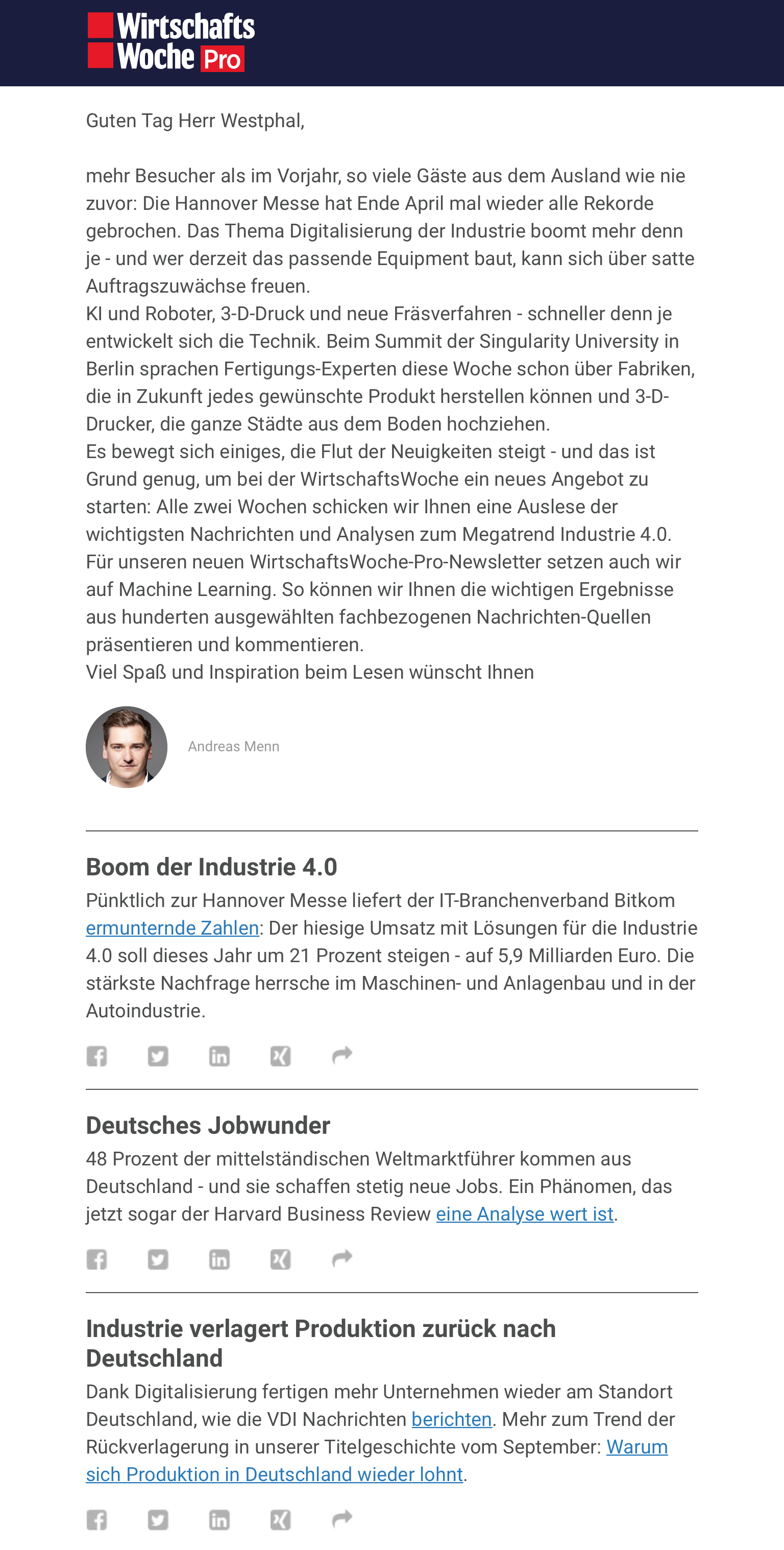
Letzten Sommer haben wir gemeinsam ein kleines, intelligentes Tool entwickelt, das Fachredakteuren bei der Informationsrecherche, Kuration und Newsletterveröffentlichung behilflich sein soll. Diesen Mai nun hatte WiWo.Pro seinen Stapellauf. Ein kurzer Projektsteckbrief und Werkstattbericht unserer Erfahrungen.
Die Idee für das Projekt war noch ein Jahr früher geboren. Holger hatte ein themenspezifisches Recherchetool vor Augen, mit dessen Hilfe man
in kürzester Zeit alle wichtigen Quellen eines spezialisierten Themenbereichs verfolgen,
direkt eine für die Leser kuratierte und kommentierte Auswahl von Artikeln treffen und
mit wenigen Klicks einen hochaktuellen Newsletter über die Entwicklung einer Branche erstellen konnte.
Please meet WiWo.Pro.
Die kleine eigene Suchmaschine
Zur individuellen Themenrecherche sollte jeder Redakteur die Möglichkeit bekommen, seine bevorzugten Quellen einzustellen. Um Bias und Filterblase zu umgehen, wollten wir dabei möglichst nah an Originalquellen und Autoritäten herankommen und die Entwicklungen direkt aus Universitäten, Forschungseinrichtungen, Unternehmen, Fachpresse und Expertenmeinungen aufgreifen.
Aus diesem Grund nutzen wir einen fokussierten Web-Crawling-Ansatz, den jeder Redakteur jederzeit mit einem kleinen Stups darin steuern kann, wie wichtig welche Quelle für eine Branche ist. Fürs erste kann unser Tool das große weite Web absuchen wie auch Twitter. Weitere Datenquellen ließen sich jedoch leicht anschließen. So wäre beispielsweise ein E-Mail-Gateway denkbar oder eine Schnittstelle zum Import von Rich-Text-Dokumenten wie PDF, MS Word & Co.
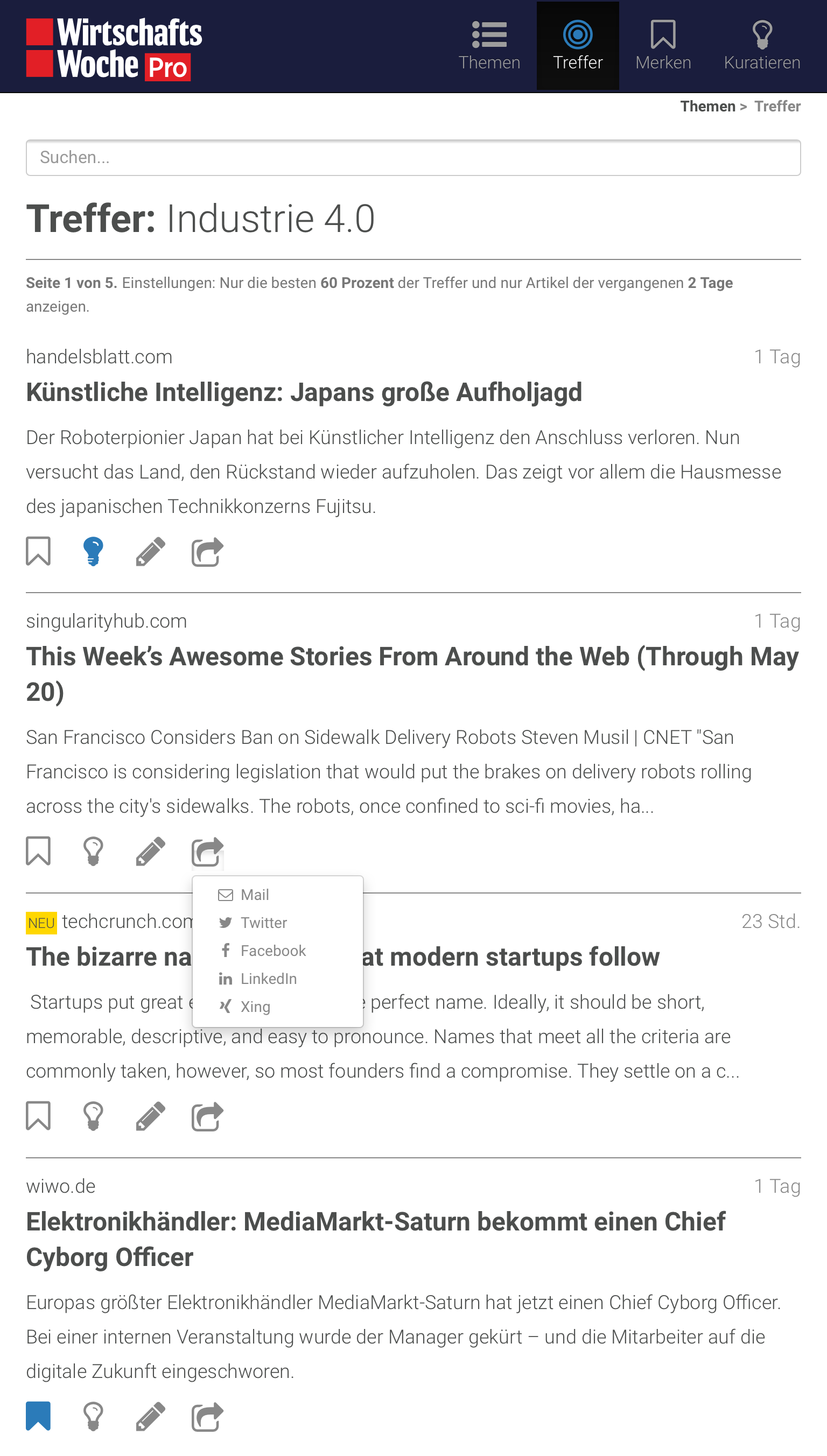
Meine Schlagwortwolke, meine Trefferliste
Dennoch sind viele Artikel relevanter Quellen nicht zwangsläufig auch von hoher Relevanz. Es galt die große Menge eingehender Dokumente noch danach zu filtern, ob ihre Inhalte tatsächlich dem gesuchten Themenfokus entsprechen. Dazu mussten wir den eigentlichen Inhalt einer Webseite im HTML-Dokument erst einmal identifizieren, extrahieren und textlich analysieren.
Unser erster Testpilot Andreas Menn schlug deshalb zur Schwerpunktsetzung ein minimales Interessenprofil vor. Über zwei Arten von Schlagworten kann jeder Redakteur nun sehr genau sein Themenspektrum definieren und somit steuern, welche Artikel für die eigene Trefferliste relevant sind (notwendige Keywords) und welche die Wichtigkeit noch steigern (zusätzliche Keywords).
Recherchieren, kuratieren, publizieren
Das Werkzeug sollte möglichst flexibel einsetzbar sein. Ob zur reinen Recherche, zum Bespielen der sozialen Plattformen oder zur Produktion regelmäßiger Newsletter, wir wollten eine möglichst einfache Basis schaffen und viele verschiedene Workflows unterstützen.
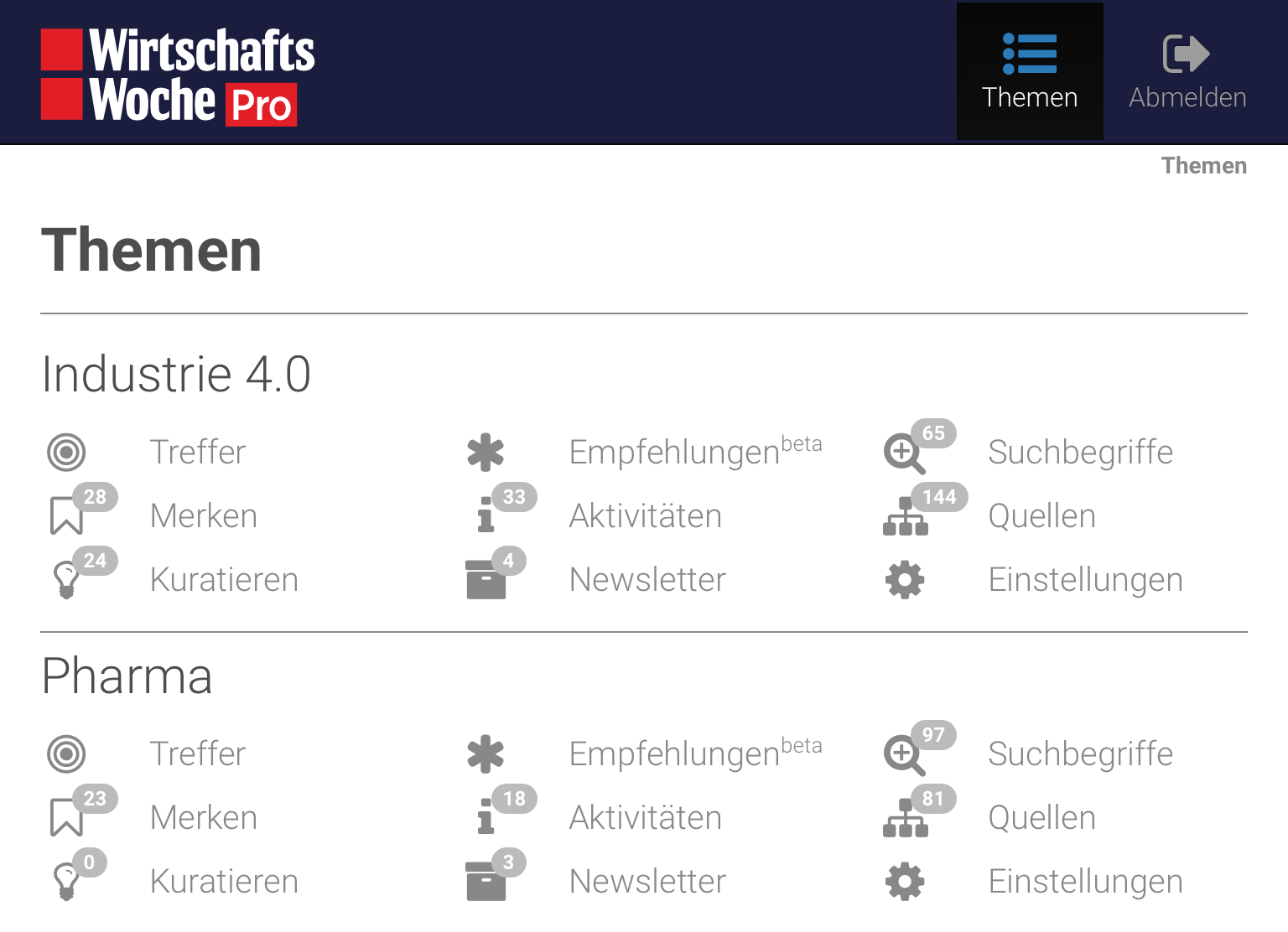
Unsere Benutzerschnittstelle führt daher wie ein Trichter auf unterschiedliche Endprodukte hin, schreibt den Nutzern jedoch keinen starren Arbeitsablauf vor. Drei im Wesentlichen identische Ansichten lassen den Redakteur flexibel zwischen generierten Suchtreffern, eigener Merkliste und verfassten Texten hin und her wechseln.
Eine Newsletter-Vorschau stellt die vom Redakteur kuratierte und kommentierte Auswahl von Links letztlich im späteren Mail-Template dar. Das Mailing kann dann sofort versendet oder für einen festen Zeitpunkt geplant werden. Das Responsive Design der E-Mail war leider kein leichtes. Da MS Outlook kein einfaches Ziel ist, haben wir hier viel Zeit verloren.
Empfehlungsmaschine (noch beta)
Suchtreffer können immer mal falsch positive Ergebnisse enthalten. Zunächst hatten wir vor, die Algorithmen mit einem als-Spam-markieren-Knopf zu trainieren. Da Menschen falsch eingeordnete Artikel jedoch meist sehr zuverlässig erkennen, haben wir uns schließlich für die entgegengesetzte Strategie entschieden und eine einfache Empfehlungsmaschine gebaut.
Zum über-den-Tellerrand-schauen greifen wir jetzt auf einen Random Walk aktueller Webseiten zurück, die mittels eines neuronalen Netzwerks nach Relevanz klassifiziert werden. Die generierten Ergebnisse sind, obwohl wir nicht viel Zeit in die Maschinerie stecken konnten, von erstaunlich guter Qualität.
Da die Artikel allerdings aus einem unstrukturierten Web-Crawl stammen, fehlen uns zu einigen Quellen nur oft wichtige Metadaten. So können wir den Publikationszeitpunkt einiger Dokumente zum Beispiel nur heuristisch ermitteln und somit die für einen Newsletter notwendige Aktualität noch nicht vollständig per Automatik gewährleisten.
Aktivitäten-Stream für die Teamarbeit
Wird ein Fachthema von mehreren Redakteuren betreut, und sei es auch nur zur Urlaubsvertretung, so wollten wir die Zusammenarbeit gerne darin unterstützen, dass die Kommunikation untereinander so weit wie möglich in der App selbst stattfinden kann.
Inspiriert durch Open-Source-Plattformen wie GitHub bieten wir deswegen einen News-Feed jüngster Aktivitäten an. Denkbar wären hier noch themenübergreifende Mitteilungen, um interessante Links direkt an den Themenkanal von Kollegen senden zu können. Oder eine Undo-Funktion für wichtige Aktionen.
Maschinelles Lernen lässt das Tool fortlaufend dazulernen
Der Dienst ist gerade erst gestartet. Mittelfristig wünschen wir uns jedoch, dass das Tool mit der Zeit aus den Präferenzen der Redakteure automatisch lernt, passendere Ergebnisse zu liefern.
Überaus nützlich wäre zum Beispiel, die Nutzer darüber zu informieren, welche ihrer Quellen und Schlagworte überdurchschnittlich effektiv genutzt werden, welche eigentlich unterdurchschnittlich. Wir könnten neue Quellen und Schlagworte automatisch vorschlagen, ihre Gewichte je nach Nutzungsszenario tunen und korrigieren, die Empfehlungsfunktion zentraler integrieren... Mit etwas Data Science lässt sich das Produkt weiter und weiter verbessern.
Danksagungen
Für die tolle Zusammenarbeit ein herzliches Dankeschön an das WiWo.Pro-Team: Holger Windfuhr, Léa Steinacker, Andreas Menn, Jan Lepsky.
Holger Windfuhr ist zum Jahresbeginn als Art Director zu Frankfurter Allgemeine Zeitung gewechselt.
Das WirtschaftsWoche-Projekt wurde gefördert durch die Google Digital News Initiative.
Die ersten beiden WiWo.Pro-Newsletter zu Industrie 4.0 und Pharma können Sie jetzt auf wiwo.de abonnieren.
Updates: Das Produkt heißt inzwischen ProFound. Als weiteres Thema gestartet: Cybersicherheit. Alle Experten-Newsletter.