– Es begab sich so im Oktober 2008 zu einer Zeit, in der ich nur einen einzelnen Server hatte. An jenem Morgen gab Rivva kein einziges Lebenszeichen mehr von sich. Dennoch: Ich konnte mich ohne Umwege auf der Maschine anmelden. Was war hier los?
Wie sich zu meiner Überraschung herausstellte, war überhaupt nichts los. Die Kiste war praktisch in Ruhe:
top: Keine Last.
ps: Prozessliste normal. Dann:
dmesg: Im syslog kein einziger Hinweis.
Nichtsdestotrotz: Das System lief ja überhaupt nicht mehr!???
Reflexartig:
df: 0% Plattenplatz.
Ahso! Nur wie denn das, bitte schön?
Erstes Hindernis: Rettung und Rekonstruktion sind gar nicht so einfach, sind die Festplatten erst einmal zu 100% vollgelaufen. Der Linux Kernel läuft scheinbar unbeeindruckt weiter. Nur dass eben jede, wirklich kleinste Schreiboperation sofort zum Abbruch führt. Jetzt noch ein Programm zur Fehlerdiagnose installieren, haut nicht mehr hin.
Ich fand bald heraus, dass zwei der Logdateien meines Crawlers eine Größe von je vielen hundert GBs erreicht hatten. Wie das Logging so aus dem Ruder laufen konnte, dazu musste ich anschließend erst einmal meinen Code befragen.
Hier das Szenario, wie es sich in der Nacht abgespielt haben muss. Die Kettenreaktion hat mich schwer beeindruckt:
Ein Blog hatte das Abrufen seiner URL inmitten der Dateiübertragung abgebrochen, aber Status 200 OK übermittelt.
Die Präambel des Downloads gab an, das Datei-Encoding wäre ISO-8859-1.
Mein Crawler normalisiert alle Inhalte auf UTF-8-Kodierung. Also kurz iconv angeworfen…
Hier geschah das erste Unglück: Die Datei war ja unvollständig. Der Konverter generierte daraus eine nicht mehr enden wollende Reihe von Zeichen. Eine Endlosschleife im endlichen Automaten!?
Mein Bot brach ab und protokollierte die Fehlerursache. An dieser Stelle geschah der zweite Fehler: Ich hatte den dummen Bot so programmiert, dass er die komplette Exception Message loggen sollte. Die nicht enden wollende Reihe von Zeichen wurde so auch noch hübsch auf Platte gebannt: Hunderte Milliarden Mal wiederholte sich ein und die selbe Bytesequenz.
Die Festplatte war jetzt zu circa zwei Drittel gefüllt. Noch ist alles gut. Bis Stunden später ein wichtiger Job seine Arbeit machte…
Morgens in der Früh rotiert ein logrotate Daemon alle Logdateien des Systems. Die Anweisung lautet copytruncate, d.h. das originale Log File wird gekürzt, nachdem eine Kopie erstellt wurde. In diesem Moment nimmt der Schaden seinen finalen Verlauf. Für die Kopie ist endgültig kein Platz mehr. Oy vey!
Was lehrt uns dieser Fall? Protokolliere Fehlernachrichten nie in voller Länge (jedenfalls solange sie außerhalb der eigenen Codegrenzen generiert werden).
Auch nach Jahren finde ich diesen Bug immer noch ausgesprochen hübsch.
Vor sieben Jahren ist mein TDD-Buch erschienen. Das Buch beschreibt, wie man Software in kleinen sicheren Schritten entwickelt.
Mittlerweile ist es nicht mehr im Druck. Als Autor möchte man natürlich so weit und breit wie möglich gelesen werden.
Ich freue mich deshalb riesig über das Einverständnis des dpunkt.verlags, das Buch ab heute kostenlos als eBook anbieten zu können.
– Nicht wundern: Auf Rivvas Seiten steht jetzt Partner von Populis. Die mokono GmbH, die rivva.de exklusiv vermarktet, wurde ja bereits im September hundertprozentige Tochter von Populis und hat nun gestern auch den Namen der Muttergesellschaft übernommen. Glückwunsch: Vasco & Florian.
Ebenfalls gestern haben die Carta-Herausgeber ihre aktuellen Pläne veröffentlicht. Es freut mich, wie es mit dem großartigen Autorenblog weitergeht und dass ich ein wenig im Wissenschaftlichen Beirat helfen darf. Glückwunsch: Tatjana, Wolfgang, Leonard & ganz besonders Vera.
– Meine Historie mit der re:publica (und Berlin-Terminen allgemein) ist leider unter aller Kanone. Zwei eingeladene Vorträge musste ich schon wegen Krankheit in letzter Sekunde absagen.
Aus dem Grund hatte ich Philip Banse zunächst geantwortet, dass das Risiko einer dritten Blamage einfach zu groß sei. Doch nun freue ich mich, doch zugesagt zu haben und endlich mal die Konferenz zu besuchen.
Die Gesprächsrunde findet statt am Donnerstag um 1615 Uhr: Blogger im Gespräch.
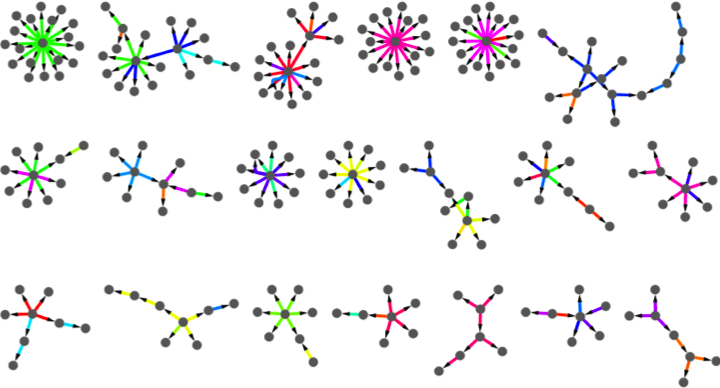
Wunderschöne Informationskaskaden aus dem Paper von Kwak, Lee, Park und Moon [1].
– Im letzten Jahr hab ich fast jeden Tag ein Research Paper gelesen und bin dadurch mit jeder Menge neuer Themenfelder in Kontakt. Derzeit führt meine Exkursion quer durch die Twitter Social Science.
Die Sozialwissenschaftler lieben Twitter. 340 Millionen Tweets pro Tag. 140 Millionen aktive Nutzer. Ein sozialer Graph mit wahrscheinlich Billiarden gerichteter Kanten? Nie zuvor hatten die Soziologen so viele, wertvolle Daten zur Hand. Und das noch nahezu in Echtzeit.
Weil sich die Forschungsergebnisse unmöglich zusammenfassen lassen, einige Meta-Anmerkungen:
Ein Vorhaben [22] stammt aus Deutschland. Ein weiteres [9] mit Beteiligung.
In einer Untersuchung [20] taucht #winnenden auf.
Circa ein Dutzend der Projekte trifft die naive Annahme, dass die Nutzer von Twitter tatsächlich alle Tweets der Verfolgten auch verfolgen. (Hmmm…)
Ein Team [2] geht der Rolle der Twitter Search und Public Timeline detaillierter nach.
Zwei Teams [16, 26] untersuchen die Fremdbestäubungseffekte sich überlagernder sozialer Netzwerke.
Mehrere Analysen legen ad hoc Potenzgesetze zugrunde, mit stark schwankenden Exponenten. (Sind wissenschaftliche Arbeiten, die kein Power Law ausrufen, wertlos geworden?)
Was mich wurmte: Da werden vielerlei Millionen von Status-Updates, Millionen von User-Profilen und Milliarden von Follow-Beziehungen erhoben, um anschließend nur die top-k Tweets, Hashtags, Trending Topics auszuwerten? Mit k im Mittel 500? Wieso nicht Long Tail, Fat Tail, Unknown Unknowns?
Ein Team [10] stellt die Frage nach der Sampling-Methode.
„It's not when people notice you're there that they pay attention; it's when they notice you're still there.“ – Paul Graham, Hackers & Painters, p. 211
– Im letzten Jahr hat das Rivva Blog arg wenig Liebe bekommen. Zukünftig möchte ich wieder häufiger über die Entwicklungen bloggen.
Insbesondere habe ich eine Artikelreihe in Arbeit, die den Aufbau und die Funktionsweise einmal von A bis Z erklären soll. Das wird eine wohl mehrjährige Expedition werden und ausgesprochen viele Themen diskutieren.
Für Hintergründe taugen die Gespräche oft besser. Das neueste Interview ist bei 1000ff zu lesen. Zur Rückkehr schon erschien eines bei artundweise und im Herbst ein erstes Fazit bei Meedia. Hier bereits verlinkt waren 140 Sekunden und DRadio Wissen. Vasco Sommer-Nunes (mokono) kam beim Werbeblogger zu Wort.
Woran habe ich die Monate gearbeitet? Die meiste Zeit ist tatsächlich fürs Yak Shaving hopsgegangen. Ich bin dabei, große Teile des Systems neu zu programmieren. Gleichzeitig ziehe ich Komponenten, Module und APIs heraus, um darauf aufbauend eigene Produkte zu entwickeln. Ich möchte dieses Jahr auch erste Projektteile als Open Source freigeben, um damit an die Community zurückzugeben.
Was ist für 2012 zu erwarten? Ein neues Ranking ist in Planung. Dem Twitterspam soll endlich der Garaus gemacht werden. Die Topic-Seiten, Themen-Cluster und verwandten Stories finden zurück. Große Neuerungen wird es dann erst 2013 geben, da die Produktentwicklung zunächst im Fokus steht. Rivva benötigt ein zweites und drittes Standbein.
– In der Vergangenheit war die Logdatei hauptsächlich ein Protokoll jener Systemereignisse, die später zur Diagnose des Programmverhaltens und der Fehlerbehebung dienen sollten. Doch das ist nicht mehr gut genug.
A/B Testing, Realtime Analytics, Data Science uvm. haben die Rolle der Logs erweitert. Konsument sind nicht mehr nur Menschen, sondern zunehmend andere Maschinen.
Rivvabot loggt gerne und viel. Ich war nun auf der Suche nach einer Lösung, die mich echte, beliebig schachtelbare Datenstrukturen loggen lässt und die gleichzeitig meinen Code vom Logging Clutter säubert.
intent, success und error sind hier Log-Anweisungen, die ich als Kernel Methods in alle Ruby-Objekte reingemixt habe und die im Initializer an konkrete Log-Levels (debug, info, warn, error, fatal) gebunden werden. Mir gefällt daran, wie das Logging dem Code eine fast narrative Struktur gibt.
Die hier protokollierten sieben Attribute werden nicht mehr im dummen Format String in ein Log File geschrieben, sondern als semistrukturierter JSON String, einfach zu parsender Key/Value-Paare, zum zuständigen Event Collection Server gestreamt. Als Log Aggregator setze ich Fluentd ein.
Fluentd nun sammelt die Logs aller Nodes in einer Mongo-Instanz. Da MongoDB dokumentenorientiert ist, wird jede Log Message mit all ihren Feldern indiziert und damit beliebig queryable.
Vorerst pusht Rivva nur um die 2,4 Millionen Events täglich, insbesondere weil ich immer noch mit der Größe von Mongos Capped Collection experimentiere (momentan: 1 GB, Tradeoff: Speicherbelegung vs. Langzeitarchivierung).
– Auch Rivva wird sich am 18. am Netzprotest gegen SOPA und ACTA beteiligen und für 12+ Stunden die Lichter ausknipsen.
"Stop SOPA" war eigentlich häufig genug Titelstory. Gute Argumente gegen den Stop Online Piracy Act liefern bspw. der Breitband-Beitrag vom Samstag und Joi Ito.
– Thomas Reintjes und Sebastian Sonntag hatten mich heute morgen als Gast im Online Talk. Nachzuhören gibt es den Beitrag als MP3-Download oder man abonniert gleich den Podcast.
– 2011 bleibt für mich als das Jahr in Erinnerung, in dem Rivva das Blatt noch einmal wenden konnte. Knapp dem Projekttod entronnen, hat die Seite unterdessen sogar seine Leserzahlen verdoppeln können. Mein Dank dafür gilt allen Fürsprechern sowie mokono und BMW i, ohne deren Unterstützung das alles gar nicht möglich gewesen wäre.
Es freut mich daher außerordentlich, euch heute das Update geben zu können, dass BMW i die Werbepartnerschaft durch mokono für das gesamte Jahr 2012 verlängert. Mir fällt damit ein Stein vom Herzen und für das gesamte deutschsprachige Social Web ist es auch eine wunderschöne Bestätigung. Danke!
Hier findet ihr die finale Ausgabe vom Jahresrückblick 2011: http://rivva.de/2011 Die Daten zwischen Februar und Juni habe ich soweit wie möglich aufgearbeitet. Ich wünsche euch allen ein gesundes und glückliches neues Jahr.