Webstatistik: Wie viele Webdomains verwehren den neuen Webcrawlern jeglichen Besuch ihrer Seiten?
–
Heute kucken wir uns mal 150.000 robots.txt-Dateien an:
Mich interessierte im Detail, wer die "KI-Crawler" von GPT, Common Crawl, Google und Apple eigentlich überhaupt noch auf seine Website lässt.
Dass mittlerweile fast alle Nachrichtenseiten die GenAI-Bots aussperren, hatte ich ja schon vorletztes Mal über Common Crawl gepostet.
Dass offenbar aber generell eine starke Gegenwehr auf dem Weg ist, die eigenen Webinhalte vor der Verwertung durch generative KIs zu schützen, verdient eine zweite, tiefere Betrachtung.
Zum Vorhaben:
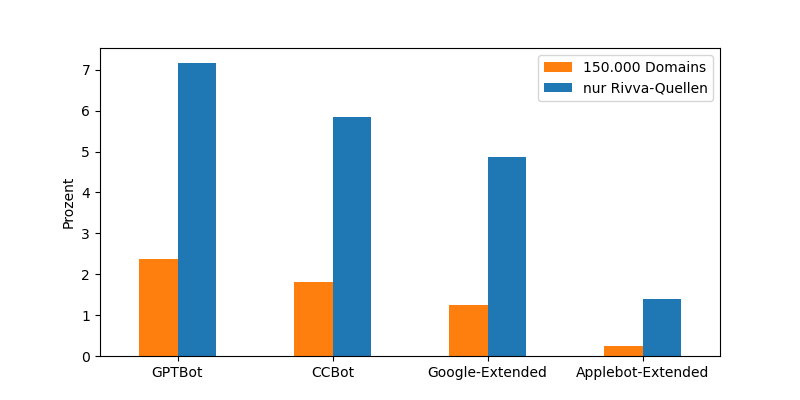
150.000 Domains nach Zufall selektiert; davon 80% deutsch, 20% englisch; ohne Einfluss, wie lang die Site schon existiert, wie oft verlinkt oder welcher Art von Angebot
3,4% davon verbannen gleich mal alle Bots; diese Seiten wollen also auch in keiner Suchmaschine auftauchen und bleiben im Weiteren ohne Betracht – es soll hier nur um explizite Auslistung der KIs gehen
aktuelle robots.txt abgerufen im letzten Monat
150.000 Stichproben können nicht repräsentativ sein, nur eine Momentaufnahme, kein Trend
Das Ergebnis (mit Startpunkten der User-Agent-Kennungen in Klammern):
GPTBot: 2,4%(August 2023)
CCBot: 1,8%(März 2008)
Google-Extended: 1,2%(September 2023)
Applebot-Extended: 0,2%(Juni 2024)
Anschließend habe ich die Liste nochmal auf Rivva-Quellen eingeschränkt (~10.000 Domains):
– OpenWebSearch.eu ist das europäische Pendent zu Common Crawl.
Das Ziel: ein offener Webindex (+ Services) = Datensouveränität für Europa.
Das Projekt ist EU-finanziert und fördert seinerseits Community-Projekte.
Leider habe ich den Call zu knapp vor Bewerbungsfrist entdeckt – entsprechend aus der Hüfte geschossen war meine (jetzt abgelehnte) Idee.
Title
Federated Search Directories
Target Field of the Research
Curation of search result sets: Are end users willing / able to establish useful / valuable search directories for their favorite topics / area of expertise?
Federation: Will the pool of directories improve through collaboration?
Approach and main challenges: describe your approach, methodology
This project will investigate the question if old-school search directories, curated by expert users, could be a feasible alternative to today’s paradigm of “10 blue links per page ranked by some algorithm”.
It will empower end users to help their fellow humans navigate the web in a new old way and hopefully show them the beauty and knowledge that the “long tail” of the web entails.
This approach is going back to a time when the web was so small that books where printed with lists of recommended starting points (I still have my copy of O’Reilly’s “The Whole Internet”), when Yahoo established their famous web directory, and when this format was the status quo (I worked on one of the oldest sites which is still online) because literally everybody could do it with a little knowledge about basic HTML.
Approach and main challenges: expected outcomes, relevance
Mainstream search engines are plagued with SEO and redundant content. Also, they have business interests that are counterproductive.
If people can curate and share their own favorite search results / starting points, we might get back to the experience that the web was new and exciting, and not dominated by the same 10 big companies every time you want to look something up.
If we then aggregate this “human” signal, we might find out what people really like. Back to a time when links were endorsements, not paid for.
Describe the contribution to the component(s) in detail
Search Applications: Starting with a known starting point URL or a given query, we give the user the opportunity to mix and match relevant information with similar search results. I’d also like to experiment if a “random walk” component (like that in the original Google rank formula) could be of any help to prevent the problem of “too much choice” on the users.
Users can then build URL bundles that have their own URL, will be hashtag-able, will be searchable, clonable (notifying the original author), can be shared, embedded on other sites and so on. The search result set will become a “social object” with an REST API interface.
With similarity metrics and vector based representations, we could then both recommend new URLs entering the search index and built detail hierarchies and tags-onomies of the user generated content.
Search Paradigms: As described above, this project will be answering the question if search directories are still useful in 2024 or could become more prominent in the future. Can we find new signals / weights in this user generated data?
–
Diesen Monat hat Common Crawl seinen 100. Crawl veröffentlicht.
Wer damit nichts anzufangen weiß:
Common Crawl ist ein offener Webkorpus, einige Petabytes groß und eben deshalb *die* Trainingsbasis fast aller großen Sprachmodelle.
60% der Vortrainingsdaten für GPT-3 stammten aus einem gefilterten Common Crawl.
Generative KI wäre ohne den Common Crawl nicht möglich gewesen.
Und das genau ist auch das erklärte Ziel des Non-Profit:
Webdaten verfügbar zu machen, auf die sonst nur Big Tech Zugriff hätte.
Ich hatte mir Common Crawl schon lange nicht mehr angesehen und wollte daher einfach mal untersuchen, wie es denn heute um deutschsprachige Inhalte steht.
Analysiert wurde das Inkrement #100, eingeschränkt auf den URL-Raum aller .de-Adressen:
Die Schnittmenge zwischen Monatsarchiven liegt inzwischen im einstelligen Prozentbereich und der Fokus auf .de-Domains war eine kostengünstige Approximation der viel aufwendigeren Sprachenerkennung.
Gezählt habe ich
3.224.547.295 unterschiedliche URLs
145.099.211 (4,5%) davon in einer .de-Domain
in insgesamt
69.342.933 unterschiedlichen Domains
5.614.859 (8,1%) davon mit .de-Endung
Die Qualität des Indexes ist bewusst inklusiv gehalten.
Wer forscht, muss sich den interessierenden Ausschnitt aus dem Ausschnitt selbst erzeugen.
Die Datenmengen sind zwar groß, aber noch praktikabel.
Filter- und Blocklisten sind eure Freunde, Verzerrung in den Ergebnissen dann leider die Folge, doch der Common Crawl als solches ist schon nicht ohne Bias.
Lest dazu das hervorragend recherchierte Papier von Stefan Baack.
Oder schaut einfach seinen re:publica-Vortrag.
Als Nächstes wollte ich die Schnittmenge zwischen Common Crawl und meinem eigenen Crawl ermitteln.
Dafür habe ich aus den im Zeitraum Q1/2024 von Rivva erstmalig gefundenen URLs 50.000 zufällig ausgewählt und mit dem Mai-Archiv von Common Crawl verglichen.
Heraus purzelten 4.907 Seiten von 323 verschiedenen Sites (darunter auch ein paar englischsprachige, die mein Bot immer noch verfolgt).
Für die Forschung ist so ein monatlicher Schnappschuss völlig ausreichend.
Viele Anwendungen verlangen jedoch einen Echtzeitindex.
Deshalb hat OpenAI mittlerweile auch seinen eigenen Bot.
Wenn dieser nicht blockiert würde…
Also habe ich zuletzt geschaut, wer hierzulande eigentlich die "GenAI-Bots" überhaupt noch zulässt per robots.txt:
GPTBot wird von keiner der großen Nachrichtenseiten mehr geduldet, Ausnahme sind die öffentlich-rechtlichen Angebote
CCBot dito, nur ein Haus hat ihn noch nicht gesperrt… findet ihr leicht heraus
Google-Extended ebenso durch die Bank blockiert, mit ganz wenigen Ausnahmen
Applebot-Extended ist erst wenige Tage alt, vier Mal habe ich die Sperrklausel mit Stand heute entdeckt
Wer selbst nachsehen möchte, ob die eigenen Seiten im Common Crawl enthalten sind, hier entlang und einfach Sternchen an eure Adresse anhängen.
∀ Nerds: Diese Projektpräsentation von Sebastian Nagel ist ebenfalls exquisit.