– Als ich diesen Projektvorschlag für den Google DNI Fund eingereicht habe, war ich so zuversichtlich – und meinte: „Das ist wichtig, das kann gar nicht abgelehnt werden.“ Leider doch!
The internet is broken and we have to fix it. Recent years have seen an alarming increase in "toxic" communication in comments sections all around.
People wishing to express themselves are leaving the conversation because of abusive, hateful or otherwise anti-social speech. Several prominent news sites have shut down their discussions forums entirely, seemingly having given up on thoughtful audience feedback altogether.
I'd like to develop a tool for publishers that helps like a spam filter so that the civil exchange of ideas and different opinions becomes possible yet again.
Detailed description:
Todays tone and behaviour in news discussions is reaching toxic levels, ultimately driving intelligent people away. This happens at a great loss for societal progress because the story and discussion around the fireplace is an age-old tradition of our species.
The assumption being tested with this prototype is that the careful application of the so-called "broken windows theory" supported by a bag of matching moderation tools could help restore our values in online conversation. According to the broken windows theory, "visible signs of crime, anti-social behavior and civil disorder create an urban environment that encourages further crime and disorder […]. The theory thus suggests that policing methods that target minor crimes […] help to create an atmosphere of order and lawfulness […]." (source: Wikipedia)
Carefully moderated comments sections offer rich debate and useful information for both journalists and readers. And who is not pleasently surprised when the comments below an article turn out to be even more useful than the original article? Even though content moderation poses substantial time investment on the publishers' side, it saves a multitude of this time on the consumers' side to sort through comment columns. Equipped with better tool support, moderators could keep these democratically so important discussion spaces alive and at a lower cost, but not so lively that they have to be turned off. As we know, the dosage makes the poison.
The prototype will do a job comparable to your spam filter and predict the probability that a user comment demonstrates abusive or in other regards offensive language. Flagged comments could then be sorted in ranked order according to "toxicity" indicators or trending topic to point moderators to the most controversial or fastest developing poisonous comment threads that deserve their attention first. Nobody would dispense with their email spam filter but when it comes to content moderation we could do with much more and better tool support as well.
The same functionality could be provided to readers and commenters on the news site. Readers could choose themselves via slider interface to filter out comments above a certain threshold of profanity, while commenters would get immediate feedback on the consequences of their writing.
Comments that would likely register at toxic levels would include those that contain hate speech, are off-topic, contain name-calling, are without substance or fit other offensive criteria for being sent to moderation. Perspective API (see below) currently recommends that no comment be automatically banned by the algorithm. Human judgement should be the basis for the final decision. The tool would guide the moderator by ranking the comments in order of attention needed, and the moderator would guide the tool by making the final call that the tool can learn from for scoring future comments.
What makes your project innovative?
This project will supply a prototype implementation for identifying, classifying and managing toxic comments.
Because I am not a content provider myself this project would be transformative to me if I could become a technology provider in the respected area. Through the web crawl corpus that my service rivva.de has archived over the last 11+ years I'm in the unique position to compare and contrast conversational tonality and behaviour online over long periods of time. My goal is to sample this corpus of comments from news sites, blogs, forums, Twitter and Facebook to create the initial dataset for experimentation. Ideally the community would submit and flag even more training examples. I could include the possibility to label comments and therefore create a valuable dataset directly on rivva.de. It would fit. The site's focus has always been about the aggregation of different perspectives on the news. This repository of data then could establish a baseline and playground to evaluate the ideas described and implicated.
The technology built for this project will mainly include several natural language processing and understanding tasks.
Since language is highly ambiguous, advanced natural language understanding will be most crucial to the problem. This project would help me familiarize myself more with state-of-the-art deep learning models like convolutional and long-short-term-memory neural networks.
Key deliverables will be a new dataset of manually labelled comments for the machine learning task of classifying user generated content into different bins of toxicity as well as an API for easy integration of this task into benefitting systems.
It's essential that we account for multiple degrees of toxicity and possibly overlapping classes. What types of user comments are appropriate on a given site is usually highly dependent on its content and intended audience.
Although a team led by Google (Jigsaw) is experimenting on the very same frontier, the German language poses some unique problems in text analysis and therefore bears overlapping efforts. Especially since Germany has spearheaded the effort by its new law against hate speech.
How will your Project support and stimulate innovation in digital news journalism? Why does it have an impact?
Better tool support for the task of content moderation allows to host better conversations online.
When comments sections can be managed more effectively and more efficiently, more stories can be opened up to comments in less time. When commenters can directly get feedback on the comment they are producing, tonality and behaviour online should improve, because they want their thoughts to be published, not rejected. When readers can themselves sort comments by their toxic level, better comments sections translate into more user engagement and therefore more advertising revenue. All in all, trust in news organizations can be regained.
But most importantly, discussion spaces are way too important to leave to the big social networks. They are one of the pillars of the internet and we should fight for (almost) everyone of them. They act as a medium for change. Just think of Apple's famous "Think different" campaign: "Because they change things. They push the human race forward."
Competition:
Perspective API by Jigsaw and Google's Counter Abuse Technology team is part of a collaborative research project called Conversation AI. Its alpha version is currently being used by Wikipedia, The New York Times, The Economist, The Guardian and the Coral Project. A Kaggle data science competition on the subject and sponsored by Jigsaw has just ended.
Communities that have been operating on manual moderation with quite a success and for quite some time, often assisted by karma points, up- and down-voting systems and community ground rules, include MetaFilter, Hacker News and Reddit.
– Widmete sich die erste Projekthälfte dem Problem, Text in schön strukturierte Daten zu transformieren, will ich auf der letzten Etappe einige Möglichkeiten evaluieren, aus den Datenstrukturen Lego-artig wieder ganz neue Nachrichtenprodukte zu generieren.
Mein Ziel ist es, weitestmöglich das Living-Stories-Format zu adaptieren, dessen Prinzipien noch heißen:
Die Berichterstattung bezüglich einer Story erfolgt zusammenhängend und auf einer einzigen Webseite, der Living-Story-Seite.
Die Living Story umfasst eine laufende Zusammenfassung der Entwicklungen, die sich bisher zugetragen haben.
Der Inhalt einer Story wird durch ihre Entwicklungen organisiert.
Jede Story-Entwicklung bietet verschiedene Ansichten, die verschiedene Detaillierungsgrade enthalten, um Leser mit unterschiedlichem Interesse zu bedienen.
Jede Story-Entwicklung und jeder kleinste Inhalt wird in der Wichtigkeit für die Story priorisiert.
Um jedem Leser eine persönlichere Erfahrung zu bieten, merkt sich die Living Story, was der Benutzer bereits gelesen hat.
Visualisierung als Karte, Konzeptdiagramm und Sozialgraph
Das Format ist einfach wie genial, ermöglicht es sowohl, sich einem unbekannten Thema zu nähern, als auch, an Themen längere Zeit dran zu bleiben.
Gleichermaßen sollten verschiedene Visualisierungsformen behilflich zur Seite stehen, um komplexere Zusammenhänge zu erforschen. Etwa kartographisch, konzeptionell oder konnektiv. Und dann intra Story wie inter Story.
Klassifizierung von Textsorten
Eine Unterscheidung in Textarten (und andere feingranulare Artikelmerkmale) erscheint intelligent, sobald Leser ihre Interessen gezielt selbst lenken können sollen. (Also eigentlich immer.)
Harte Grenzen zu ziehen, entpuppte sich dabei in der Praxis als knifflige Sache. Man muss weiche Klassen bilden.
Nachtrag:
Auf der letzten Projektetappe ging mir leider zunehmend die Puste aus für die monatlichen Reports. Vielleicht hole ich das aber irgendwann nach… Nur kurz fürs Logbuch:
Monat 7: Informationsintegration für Ereignisse und Storyentwicklung, Visualisierungen als Zeitleiste
Monat 8: Sentiment-Analyse, Informationsextraktion für Medieninhalte (Bilder, Videos, Audio)
– Welche Verwandtschaft und Beziehungen bestehen zwischen benannten Entitäten? Diesen Monat wurden die Informationsschnipsel vorangegangener Monate zum Wissensgraph verknüpft.
Relationsextraktion ist die Aufgabe, Verbindungen zwischen Entitäten zu erkennen. Bringt man so in Erfahrung, dass zwei Entitäten in Beziehung stehen, könnte jeder andere Satz, der sie enthält, ebenfalls diese Relation ausdrücken. Der Wissensbaum wächst…
Relationen können binärer Natur sein, etwa (PERSON, ist-Mitglied-in, ORGANISATION), oder komplexer Zusammensetzung, möchten wir beispielsweise Geschehnisse detailliert abbilden können.
Auch die Faktenextraktion aus Monat 2 verfolgte den Zweck, Wissens-Slots zu füllen. Beim Extrahieren von Relationen kann nur zusätzlich ein Informationsschema mit ins Spiel kommen, je nach Abstraktheit der Fragestellung.
Aus den bisher extrahierten Entity-Beziehungen fand ich eine besonders spannend: (PERSON, sagte, ZITAT) fußt noch auf der Zitatdatenbank aus Monat 1, in der man nach Wer-sagt-was-über-ein-Thema recherchieren kann, wobei die sagte-Relation natürlich in viele verschiedene Ausdrucksformen aufgefächert werden kann:
– Mehrdeutigkeit, in Sprache in hohem Maße gegeben und in Schlagzeilen und Kurznachrichten vielfach sogar mit Vorsatz verwendet, stellt sprachverarbeitende Programme vor schwierigste Probleme. Mithilfe großer Wissensbasen und statistischer Inferenz können wir jedoch fehlende Weltkenntnis und gesunden Menschenverstand in Teilen simulieren.
Dieser Monat ging allein an die Datenbereinigung. Die letztes Mal extrahierten Entitäten wollten noch vereindeutigt, standardisiert und semantisch annotiert werden.
Für verlässliche Daten zu sorgen, gehört zu den wichtigsten und auch lohnenswertesten Aufgaben. Schlechte Datenqualität zieht im Allgemeinen gravierende Folgewirkungen auf anschließende Prozesse nach sich, immerhin kann jede Aus- und Verwertung nur so gut sein wie die zuvor erhobenen Daten.
Begriffsklärung benannter Entitäten
Problem Nummer eins war, dass Begriffe mehrere Bedeutungen haben und aus dem Kontext heraus auf eine Interpretation geschlossen werden muss. Identische Zeichen bezeichnen hier also unterschiedliche Objekte.
Normalisierung
Der umgekehrte Fall tritt ein, wenn die selbe Sache mehrere Bezeichnungen kennt. Wir möchten diese Duplikate erkennen, normieren und zusammenlegen (dafür Identifikator vereinbaren).
Verknüpfung
Zu guter Letzt wollen wir alle unsere Datensätze möglichst tief in einer existierenden Ontologie oder Wissensbasis verankern. Als Ressourcen dienen sich hier Wikipedia oder Linked-Open-Data-Projekte wie DBpedia an.
Diese Wikifizierung schafft den Zugang zu einer Vielzahl impliziter Informationen, die im annotierten Text nicht explizit sind, und ermöglicht somit auch, eine Reihe von Aufgaben zu lösen, die sich aufgrund des alleinigen Textes eben nicht beantworten ließen.
Ein simpler Trick zur Verbesserung eigens betriebener Suchfunktionen ist allgemein, die einleitenden Wikipedia-Paragraphen aller im Dokument erwähnten Begriffe als Mini-Dokument verkettet mit angemessenem Gewicht einfach mit in den Suchindex zu werfen.
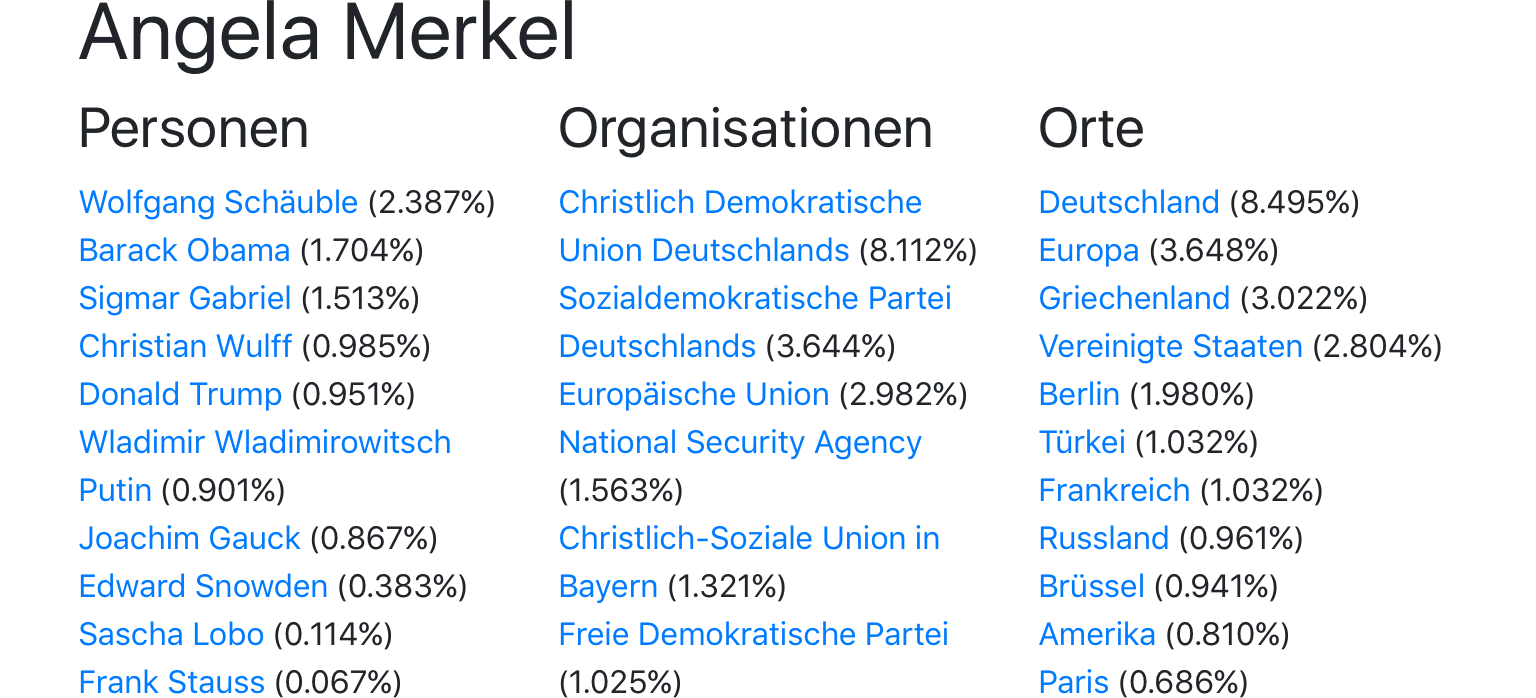
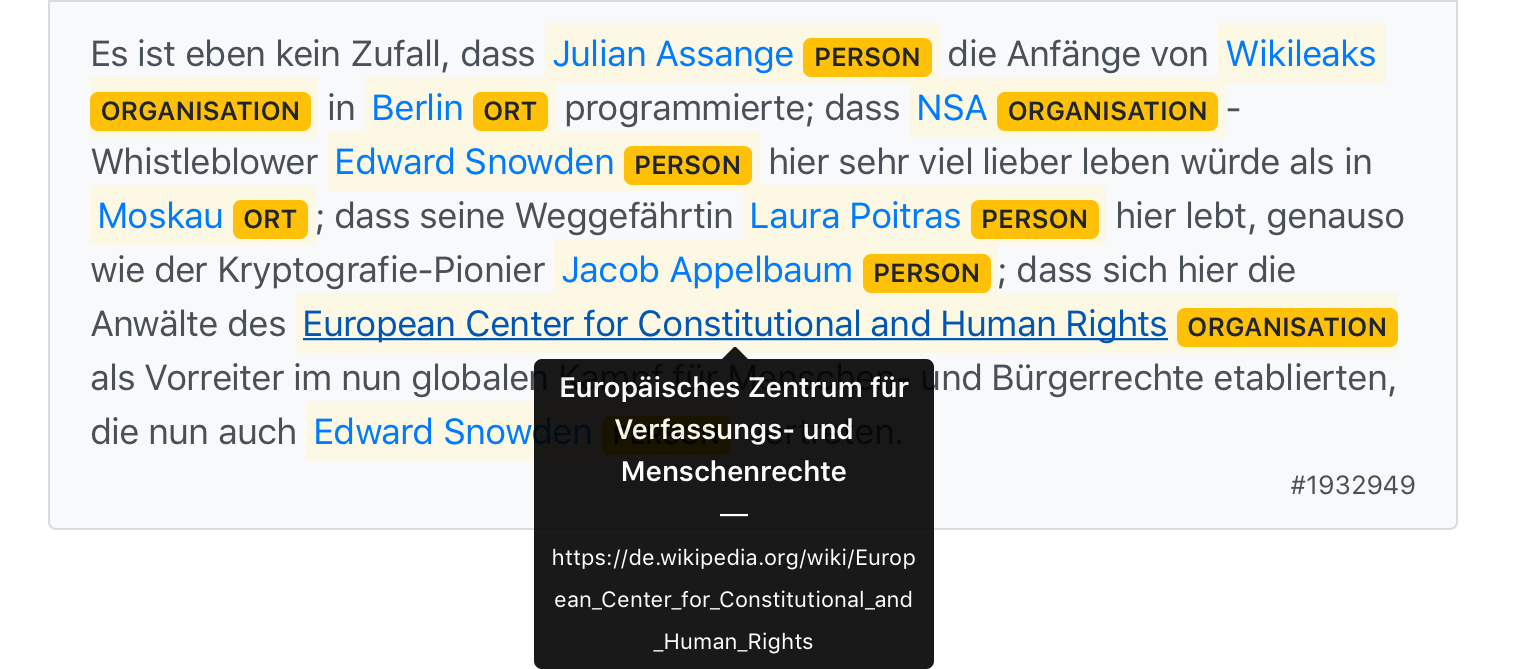
– Welche Personen, Organisationen, Orte und Produkte werden im Text erwähnt? In diesem Monat machen wir ein Häkchen an die wichtigsten Named Entities. Wobei uns stets die Mehrdeutigkeit von Sprache in die Quere kommt. Weshalb wir nächsten Monat noch unsere Daten bereinigen und annotieren werden.
Nicht ohne Sprachwitz titelte Google zur Einführung seiner semantischen Knowledge-Graph-Technologie einst "Things, not strings". Die Identifikation und Klassifikation von Eigennamen zählt von je her zu den Standardaufgaben in der Informationsextraktion.
Eigennamenerkennung
Ein Eigenname ist eine Folge von Wörtern, die sich auf eine real existierende Entität bezieht. Von Interesse sind zum Beispiel:
Personen
Organisationen
Orte
Produkte
Doch selbst die im vergangenen Monat behandelten numerischen Typen fallen im Information Retrieval gewöhnlich in das weite Themenfeld der sogenannten Named Entities:
Datumsangaben
Zeitangaben
Währungsangaben
Prozentangaben
Sobald wir diese Informationen automatisiert in Freitexten ein jeder Couleur entdecken können, lassen sich darüber schon verhältnismäßig genau die journalistischen W-Fragen einkreisen: wer? was? wo? wann? wie? warum?
Wir können sogar noch weiter gehen und jede Zeichenkette, die jemandem oder etwas einen Namen gibt, als Named Entity auslegen – je nach Anwendungskontext: chemische Formeln, gestalterische Arbeiten, historische Ereignisse, musikalische Werke, Filme, Gesetzestexte, Krankheitsbilder, Kunstwerke, Publikationen, Rezepte uvm.
Das Potenzial ist nahezu unerschöpflich, insbesondere wenn wir unsere Daten anschließend mit einem Schema – einem formalen Modell für die Struktur der Daten – ausstatten, um dieses dann kumulativ mit Metadaten auszuschmücken.
Eine Problematik ergibt sich daraus, sprachliche Zeichen (Eigennamen) auf eine Interpretation hin (das Bezeichnete) aufzulösen.
Sprache kann mehrdeutig sein (zum Teil gewollt). Nicht selten bezeichnen unterschiedliche Worte das selbe Objekt (gilt es zu normalisieren) oder es meinen identische Worte gänzlich verschiedene Objekte (zu disambiguieren).
Hinzu kommen die pathologischen Beispiele. Die Europäische Union können wir vorrangig gewiss als Organisation kategorisieren, als Wirtschaftsraum betrachtet könnte man sie jedoch gleichermaßen als Ort einordnen. Im Einzelfall und ohne Kontext meist selbst für Menschen unentscheidbar.
Facettierte Suchabfragen
Die Suchfunktion wurde indes zum Drilldown um eine Facettennavigation erweitert.
Wie wir sofort einsehen müssen, treten die oben genannten Schwierigkeiten zutage: Dubletten, die sich nur in ihrer Oberflächenstruktur voneinander unterscheiden, semantisch allerdings die selbe Sache repräsentieren.
Solche Koreferenzen zu berücksichtigen, wird eine der Aufgaben im nächsten Monat sein.