–
Rivva wird nicht eingestellt. Ich baue ein zweites.
Ich versuche noch zu verstehen, wo genau es schief gelaufen ist.
Viele haben meinen letzten Text wohl so gelesen,
als würde Rivva bald eingestellt.
Das ist nicht der Fall.
Rivva läuft weiter, so wie bisher.
Ich entwickle es lediglich in zwei Richtungen weiter:
ein stabiles altes Rivva ohne große neue Funktionen
und ein neues Rivva mit erweitertem Funktionsumfang.
Ich stelle nichts ab.
Ich stelle das Projekt neu auf.
Das neue Rivva startet konzeptionell auf der grünen Wiese
und bringt, was immer fehlte: Blogsuche und persönliches Login.
Ich habe in all den Jahren mit Rivva viele Fehler gemacht.
Trotzdem habe ich immer versucht, das Richtige zu tun,
mit Integrität und Idealismus zu handeln.
Auch dann, wenn es für mich selbst zum Nachteil war.
Wenn ich jetzt das Vertrauen gebrochen habe,
dann tut es mir unendlich leid.
Meine Kommunikation ist sicher verbesserungsfähig, daran arbeite ich.
Ich hoffe einfach, dass die meisten die Notwendigkeit verstehen
und diesen Schritt mitgehen.
Denn es gibt wirklich genug Menschen, die Rivva jeden Tag aufrufen.
Rechnerisch hätten zehn Cent pro Tag ausgereicht. Und doch …
Einen Aggregator zusammenzuhacken ist nicht schwer.
Einen, der 19 Jahre lebt, schon.
Im Fediverse las ich neulich:
„Wir werden solche Seiten noch vermissen.“¹
¹ Leider nicht als Lesezeichen gespeichert,
danke dennoch an den unbekannten Autor.
Ich wollte wissen, ob man eine Geschichte erzählen kann, ohne sie zu erzählen.
Ob man eine Welt bauen kann, die nur sichtbar wird, wenn man sich nicht frontal auf sie zubewegt.
So entstand die Story um ein fiktives Forschungsboot mit echtem Kurs: nicht vorwärts, sondern kreisend, nicht linear, sondern lemniskat – ein Schiff, das durch Zeit und Bedeutung zugleich driftet.
Für 24 Ausgaben schipperte es – im Wochentakt, mit Routine, Drift, Stille, Störung.
Ein Linkblog als Newsletter.
Aber auch: eine verkleidete Geschichte.
Die Metastruktur war von Anfang an spielerisch angelegt: Jede Ausgabe kein Kapitel, sondern ein Sektor in einem größeren Textkörper.
Lesende würden zu Archäologen, die in Fragmenten graben, Leerstellen interpretieren, Muster rekonstruieren.
Ein Newsletter, der sich wie ein verlassenes Forschungstagebuch las – oder wie ein Artefakt einer Netzepoche, die längst zu verschwinden droht.
In der achten Ausgabe hieß es: „Seit Stunden fahren wir die Acht.“
Ich schrieb das ohne Absicht – aber rückblickend war es der Moment, in dem sich alles drehte.
Etwas darin resonierte, wie ein Echo, das unerwartet zurückkommt.
Ich begann, die Oberfläche zu perforieren. Versteckte Links. Unsichtbare Anker. CSS-Fragmente, die erst sichtbar wurden, wenn man zurückkehrte. Aleatorische Verzweigungen. Zufallsschleifen. Kleine Textadventure-Einsprengsel.
Ein fädenziehendes System, das Bedeutung im Zusammenspiel mit der Leserschaft webt – wie Ariadnes roter Faden als Leitspur durch das Labyrinth der Texte.
Dann ließ ich eine Ausgabe (#13) ausfallen.
Auch die Lücke wurde Teil der Geschichte.
Mit der Zeit zerfaserte die Crew: die Funkerin rief ins Nichts, der Bordroboter loggte lückenhaft, Stimmen lösten sich auf.
Die Crew wurde zur Metapher für die vergessenen Stimmen kleiner Internetprojekte, die im Rauschen untergehen.
Stille wurde Erzählstrategie, eine weitere Textschicht.
Ich stieß an ein zentrales Problem: das der Rezeptionstiefe in einer Welt voller Scrollmüdigkeit und Ablenkung.
Es wurde der Storyteil, an dem die Crew brach.
Jetzt, zur letzten Ausgabe, kann ich es sagen: Dieser Newsletter war ein literarisches Experiment.
Ein Cybertext in Tarnung.
Ein Instrument zur Erkundung der Resonanz.
Eine Schleife, aus Worten gebaut.
Vielleicht warst du unter den wenigen, die einen Anker gefunden haben.
Vielleicht hast du gespürt, dass etwas unter der Oberfläche schwimmt.
Dann danke ich dir. Du hast die Lemniskate berührt.
Du hast gelesen, was nicht ausgeschrieben war.
Du hast gespürt, dass das Echo selbst das Signal ist.
Ich höre hier auf.
Nicht aus Enttäuschung, sondern weil die Lemniskate geschlossen ist.
Sie beginnt dort, wo sie endet.
In der achten Ausgabe.
In der stillen Mitte.
Die Schleife war die Nachricht.
Wer die Route noch einmal nachzeichnen möchte:
Im Archiv liegen alle Ausgaben – mitsamt den verborgenen Ankern.
Blogsuchmaschinen:
Sie waren einst Portale zur lebendigen Blogosphäre.
Wer in den 2000ern ein Blog hatte, fand Leser:innen.
Wer gerne las, fand neue Stimmen.
Sie halfen, Relevanz zu entdecken, Resonanz zu spüren – und machten Verbindungen sichtbar.
Heute fehlen diese Werkzeuge.
Google bevorzugt längst andere Formate.
Das Netz ist fragmentiert.
Das offene, vernetzte Web war nie weg – es ist bloß aus dem Sichtfeld geraten.
Es fehlt eine Suchmaschine, die sich wirklich für Blogs interessiert.
Deshalb möchte ich sie bauen.
Eine Blogsupersuchmaschine – smart, funktional, unabhängig.
Essenzielle Infrastruktur, um neue Blogs zu entdecken, thematisch passende Beiträge zu finden, die Vielfalt der Blogosphäre wieder sichtbar zu machen, sich zu vernetzen.
Und wer hier in den letzten Jahren mitgelesen hat, ahnt schon den Twist:
Ich suche Unterstützung.
Das Projekt soll gemeinschaftlich finanziert werden – über Mikro-Crowdfunding.
Steady statt Kickstarter.
150 Neu-Abos zu 5 € im Monat wären ein Segen zur nachhaltigen Finanzierung.
Wer das Projekt möglich macht, bekommt exklusiven Zugang zur Blogsuche – so lange die Mitgliedschaft läuft.
Als Dankeschön: Early Access.
Ein privates Forum für Ideen, Wünsche und Feedback.
Später: Ein persönlicher Feed, der zeigt, wer dein Blog verlinkt.
Und ja: Der Zugang bleibt exklusiv für die Crowd, die ihn möglich macht.
Wer schon 5+ €/Monat unterstützt, ist natürlich automatisch dabei.
Warum jetzt?
Weil das Web sich gerade neu sortiert.
Viele verlassen soziale Plattformen, schreiben wieder Blogs oder Newsletter.
Müdigkeit gegenüber Plattformlogiken trifft auf wachsendes Bedürfnis nach unabhängigen, authentischen Inhalten.
Es entstehen neue Räume.
Was fehlt, sind Tools, um sie zu finden.
Die Technik dafür ist heute besser als zu Technorati-Zeiten.
Die Chance ist da, alte Ideen neu zu denken – kleiner, klüger, gemeinschaftlicher.
Mein Angebot steht:
Ich baue dir eine Blogsuchmaschine – wenn du mir eine baust.
Klingt fair?
Dann an Bord mit dir.
Tipp: Wählt die monatliche Mitgliedschaft (Schalter über dem Paket) – so bleibt ihr flexibel, falls das Finanzierungsziel (150 neue Abos) nicht erreicht wird.
Oder per PayPal – bitte mit dem Vermerk „Blogsuche“, damit du dein Login bekommst später.
–
Ab nächster Woche gibt’s Rivva auch per Flaschenpost – na gut, per E-Mail.
Die <Anker> Ausgabe spült euch jeden Freitag das Treibgut der Woche direkt in die Inbox: Keine Kommentare, kein Klimbim – nur Links.
👀 Vom Bot entdeckt, von Hand verlesen.
📌 Sortiert nach Kategorien und den Hashtags der Woche.
💌 Kostenlos abonnierbar bei Steady.
Für alle, die lieber einmal die Woche den Anker werfen, statt ständig durch die Fluten zu paddeln.
Klingt gut?
Eure E-Mail-Adresse bleibt selbstredend unter Deck und Fach – kein Spam, kein Handel, kein Flaschenpost-Schwarzmarkt.
So sicher wie der Kiel unterm Schiff.
–
Seit 18 Jahren trotzt Rivva den Stürmen des Internets, kreuzt durch die Strömungen der Nachrichtenflut und hält den Kurs auf Qualität.
Doch der Wind hat nachgelassen, die Vorräte schwinden – und ohne eure Hilfe droht das Schiff auf Grund zu laufen.
Die Lage an Bord
Rivva war nie ein luxuriöser Ozeanriese mit Sponsoren an Deck.
Kein Medientanker mit eigener Crew.
Sondern ein kleines, wendiges Segelboot auf großer Entdeckungsreise – unabhängig und frei.
Doch die Strömung hat sich geändert.
Die alten Handelsrouten sind versiegt.
Die Seekarten, die einst verlässliche Wege zeigten, taugen nicht mehr.
Jetzt liegt es an euch, ob die Reise weitergeht oder ob der Anker fällt.
Setzt die Segel – so haltet ihr Rivva auf Kurs
⛵ Steady – ein fester Platz in der Crew!
Regelmäßige Unterstützung sichert den Proviant und hält das Schiff auf Fahrt.
→ Jetzt anheuern!
🛟 PayPal – die leere Bordkasse auffüllen!
Ob große oder kleine Spende – jeder Tropfen hilft, Rivva über den Horizont zu heben.
→ Jetzt eine Münze in die Bordkasse werfen!
📡 SOS aussenden!
Teilt Rivva mit anderen Seefahrern, werft Flaschenpost aus, lasst die Welt wissen, dass hier noch ein Leuchtturm brennt.
🧭 Neu an Bord? Noch nicht sicher, wohin die Reise geht?
Werft einen Blick ins Logbuch & Seekarten (FAQ) – dort erfahrt ihr alles über Rivva, seine Mission und warum es eure Unterstützung braucht.
Danke an die treue Crew!
Seit fast zwei Jahrzehnten hält Rivva sich auf See.
Nicht wegen Werbung, nicht wegen Investoren – sondern wegen euch.
Ihr seid die Crew, die Rivva sicher durch unruhige Gewässer bringt.
Und mit etwas Glück und Rückenwind bleibt es auch dabei.
–
Ohne euch gäbe es Rivva längst nicht mehr – Zeit, Danke zu sagen!
(2. Version: überarbeitet für mehr Klarheit)
Hallo zusammen!
Viele von euch unterstützen mich seit Jahren über Steady – die meisten sogar schon seit meinem ersten Spendenaufruf 2019.
Dafür: Vielen lieben Dank!
Aber die Zahlen werden immer kleiner.
Nur ein harter Kern von 78 Fans hält Rivva noch am Laufen.
Deshalb heute mein Aufruf an euch:
Ich will Rivva nicht nur erhalten, sondern verbessern – es gibt so viel zu tun!
Ich will noch mal die beste Version von Rivva programmieren.
Wieder experimentieren.
Schauen, was möglich ist.
Doch das geht nur, wenn ich mich eine Zeit lang voll darauf konzentrieren kann – und dafür brauche ich eure Unterstützung.
Ich habe Rivva damals für mich selbst gebaut – weil ich wissen wollte, was im Netz passiert.
Aber Software verändert sich, sobald andere sie nutzen.
Sie bekommt ein zweites Leben.
Eines, das nicht mehr nur mir gehört, sondern euch allen.
Die letzten zwei Jahre konnte ich mich kaum um den Code kümmern (erst wegen Umzug und Wohnungssanierung, dann wegen längerer Krankheit).
Jetzt sitze ich wieder dran.
Ich will Rivva besser machen als je zuvor.
Aber ohne finanzielle Unterstützung kann ich mir diese Zeit nicht nehmen.
💙 Wie ihr helfen könnt – und wie es finanziell um Rivva steht –, erfahrt ihr auf der neuen Unterstützer-Seite.
Wenn Rivva eines bewiesen hat, dann Durchhaltevermögen.
18 Jahre sind kein Zufall – sondern Ausdauer.
Der Mäander in meinem Logo steht genau dafür: Wasser findet immer seinen Weg.
Dort, wo der Spenden-Banner war, kommt bald ein Login-Link.
Die erste App ist ein kleines Dankeschön für alle, die Rivva nie abgeschrieben haben.
Vielleicht bist du ja auch dabei.
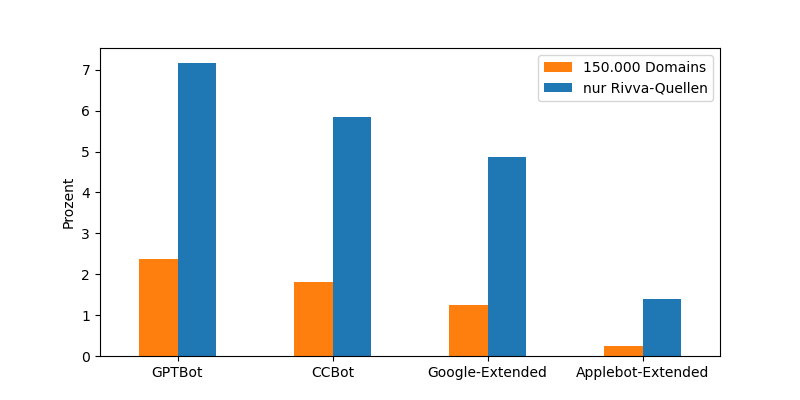
Webstatistik: Wie viele Webdomains verwehren den neuen Webcrawlern jeglichen Besuch ihrer Seiten?
–
Heute kucken wir uns mal 150.000 robots.txt-Dateien an:
Mich interessierte im Detail, wer die "KI-Crawler" von GPT, Common Crawl, Google und Apple eigentlich überhaupt noch auf seine Website lässt.
Dass mittlerweile fast alle Nachrichtenseiten die GenAI-Bots aussperren, hatte ich ja schon vorletztes Mal über Common Crawl gepostet.
Dass offenbar aber generell eine starke Gegenwehr auf dem Weg ist, die eigenen Webinhalte vor der Verwertung durch generative KIs zu schützen, verdient eine zweite, tiefere Betrachtung.
Zum Vorhaben:
150.000 Domains nach Zufall selektiert; davon 80% deutsch, 20% englisch; ohne Einfluss, wie lang die Site schon existiert, wie oft verlinkt oder welcher Art von Angebot
3,4% davon verbannen gleich mal alle Bots; diese Seiten wollen also auch in keiner Suchmaschine auftauchen und bleiben im Weiteren ohne Betracht – es soll hier nur um explizite Auslistung der KIs gehen
aktuelle robots.txt abgerufen im letzten Monat
150.000 Stichproben können nicht repräsentativ sein, nur eine Momentaufnahme, kein Trend
Das Ergebnis (mit Startpunkten der User-Agent-Kennungen in Klammern):
GPTBot: 2,4%(August 2023)
CCBot: 1,8%(März 2008)
Google-Extended: 1,2%(September 2023)
Applebot-Extended: 0,2%(Juni 2024)
Anschließend habe ich die Liste nochmal auf Rivva-Quellen eingeschränkt (~10.000 Domains):
– OpenWebSearch.eu ist das europäische Pendent zu Common Crawl.
Das Ziel: ein offener Webindex (+ Services) = Datensouveränität für Europa.
Das Projekt ist EU-finanziert und fördert seinerseits Community-Projekte.
Leider habe ich den Call zu knapp vor Bewerbungsfrist entdeckt – entsprechend aus der Hüfte geschossen war meine (jetzt abgelehnte) Idee.
Title
Federated Search Directories
Target Field of the Research
Curation of search result sets: Are end users willing / able to establish useful / valuable search directories for their favorite topics / area of expertise?
Federation: Will the pool of directories improve through collaboration?
Approach and main challenges: describe your approach, methodology
This project will investigate the question if old-school search directories, curated by expert users, could be a feasible alternative to today’s paradigm of “10 blue links per page ranked by some algorithm”.
It will empower end users to help their fellow humans navigate the web in a new old way and hopefully show them the beauty and knowledge that the “long tail” of the web entails.
This approach is going back to a time when the web was so small that books where printed with lists of recommended starting points (I still have my copy of O’Reilly’s “The Whole Internet”), when Yahoo established their famous web directory, and when this format was the status quo (I worked on one of the oldest sites which is still online) because literally everybody could do it with a little knowledge about basic HTML.
Approach and main challenges: expected outcomes, relevance
Mainstream search engines are plagued with SEO and redundant content. Also, they have business interests that are counterproductive.
If people can curate and share their own favorite search results / starting points, we might get back to the experience that the web was new and exciting, and not dominated by the same 10 big companies every time you want to look something up.
If we then aggregate this “human” signal, we might find out what people really like. Back to a time when links were endorsements, not paid for.
Describe the contribution to the component(s) in detail
Search Applications: Starting with a known starting point URL or a given query, we give the user the opportunity to mix and match relevant information with similar search results. I’d also like to experiment if a “random walk” component (like that in the original Google rank formula) could be of any help to prevent the problem of “too much choice” on the users.
Users can then build URL bundles that have their own URL, will be hashtag-able, will be searchable, clonable (notifying the original author), can be shared, embedded on other sites and so on. The search result set will become a “social object” with an REST API interface.
With similarity metrics and vector based representations, we could then both recommend new URLs entering the search index and built detail hierarchies and tags-onomies of the user generated content.
Search Paradigms: As described above, this project will be answering the question if search directories are still useful in 2024 or could become more prominent in the future. Can we find new signals / weights in this user generated data?
–
Diesen Monat hat Common Crawl seinen 100. Crawl veröffentlicht.
Wer damit nichts anzufangen weiß:
Common Crawl ist ein offener Webkorpus, einige Petabytes groß und eben deshalb *die* Trainingsbasis fast aller großen Sprachmodelle.
60% der Vortrainingsdaten für GPT-3 stammten aus einem gefilterten Common Crawl.
Generative KI wäre ohne den Common Crawl nicht möglich gewesen.
Und das genau ist auch das erklärte Ziel des Non-Profit:
Webdaten verfügbar zu machen, auf die sonst nur Big Tech Zugriff hätte.
Ich hatte mir Common Crawl schon lange nicht mehr angesehen und wollte daher einfach mal untersuchen, wie es denn heute um deutschsprachige Inhalte steht.
Analysiert wurde das Inkrement #100, eingeschränkt auf den URL-Raum aller .de-Adressen:
Die Schnittmenge zwischen Monatsarchiven liegt inzwischen im einstelligen Prozentbereich und der Fokus auf .de-Domains war eine kostengünstige Approximation der viel aufwendigeren Sprachenerkennung.
Gezählt habe ich
3.224.547.295 unterschiedliche URLs
145.099.211 (4,5%) davon in einer .de-Domain
in insgesamt
69.342.933 unterschiedlichen Domains
5.614.859 (8,1%) davon mit .de-Endung
Die Qualität des Indexes ist bewusst inklusiv gehalten.
Wer forscht, muss sich den interessierenden Ausschnitt aus dem Ausschnitt selbst erzeugen.
Die Datenmengen sind zwar groß, aber noch praktikabel.
Filter- und Blocklisten sind eure Freunde, Verzerrung in den Ergebnissen dann leider die Folge, doch der Common Crawl als solches ist schon nicht ohne Bias.
Lest dazu das hervorragend recherchierte Papier von Stefan Baack.
Oder schaut einfach seinen re:publica-Vortrag.
Als Nächstes wollte ich die Schnittmenge zwischen Common Crawl und meinem eigenen Crawl ermitteln.
Dafür habe ich aus den im Zeitraum Q1/2024 von Rivva erstmalig gefundenen URLs 50.000 zufällig ausgewählt und mit dem Mai-Archiv von Common Crawl verglichen.
Heraus purzelten 4.907 Seiten von 323 verschiedenen Sites (darunter auch ein paar englischsprachige, die mein Bot immer noch verfolgt).
Für die Forschung ist so ein monatlicher Schnappschuss völlig ausreichend.
Viele Anwendungen verlangen jedoch einen Echtzeitindex.
Deshalb hat OpenAI mittlerweile auch seinen eigenen Bot.
Wenn dieser nicht blockiert würde…
Also habe ich zuletzt geschaut, wer hierzulande eigentlich die "GenAI-Bots" überhaupt noch zulässt per robots.txt:
GPTBot wird von keiner der großen Nachrichtenseiten mehr geduldet, Ausnahme sind die öffentlich-rechtlichen Angebote
CCBot dito, nur ein Haus hat ihn noch nicht gesperrt… findet ihr leicht heraus
Google-Extended ebenso durch die Bank blockiert, mit ganz wenigen Ausnahmen
Applebot-Extended ist erst wenige Tage alt, vier Mal habe ich die Sperrklausel mit Stand heute entdeckt
Wer selbst nachsehen möchte, ob die eigenen Seiten im Common Crawl enthalten sind, hier entlang und einfach Sternchen an eure Adresse anhängen.
∀ Nerds: Diese Projektpräsentation von Sebastian Nagel ist ebenfalls exquisit.